Exploring APIs to Gather Data in Python Using the Requests Library
Table of Content
APIs are Everywhere and a Great Source of Data Projects Opportunities
One of the biggest hurdle when starting a data project is to find useful, interesting data. Many websites provide great datasets like Kaggle or Google, but the real gems hide behind APIs. What’s an API you ask? Well API stands for Application Programming Interface. It sounds pretty scary but in short APIs allow us to query applications or server using URLs and in return we receive data. Simple as that. APIs are nowadays ubiquitous and pretty much every website and application use them, see here for a ton of examples. I won’t dwelve any longer in what are APIs as the goal of this post is to learn how we can use them, but I definitely invite you to read more on the subject. To this effect I share a few links at the bottom of this article for further reading.
Now the reason APIs are great is because they give us access to data that fits our interests and/or is still unexploited. There is nothing worse than working on a project whose subject we find boring. Working on a chess dataset when you don’t care about chess is a good recipe for burnout and a series of abandonned projects in your Github repository. On the other hand I can guarantee there are APIs out there that will excite you to get started. Into cryptocurrency? we got you covered. Want to build and analyze a dataset of every Elon Musk tweet? No problem. Into US politics? Check out the FEC API. Use this list or google “[area of interest] API” and you can be sure you’ll find something.
Next regarding unexplored data and project opportunites, one of the greatest trend for public APIs these days is governments publishing public data on dedicated websites. Data about budgets, energy, climate, agriculture and many others are made available. The challenge is that often the data format is not optimal, metadata can be missing, and the data generally needs a lot of cleaning. This represents a fantastic oppotunity for data engineers and analyst that have an interest in that field. Here is an example of a few public government APIs, but feel free to explore what your country has to offer:
- US government open data
- Canada open data portal
- Open government data platform India
- France open data
- Australia public data
Finally, in addition to the fun they can provide APIs offers many tangible benefits:
- We use them at work. Some services and applications we pay for at work often have more or less hidden APIs. If you are already experienced and know how to extract their content and automate certain tasks you can generate a lot of value, especially for non-technical users.
- We can build great side projects / portfolios using them. Imagination is the limit: create a complete data pipeline to extract, store, and display stock prices or you favourite NBA players stats, build a real estate price evolution dataset, or track and display Fitbit health data. APIs offer many possibilities.
- Business opportunities. Some companies provide paid access to their APIs (e.g. financial data) that we can use to build products on top of them. Who knows, your side project might morph into a profitable venture.
- They look good in your github portfolio. A cool project in your Github profile leveraging an API can be a great ice breaker during an interview and lead to far more interesting discussions than we could gather from a take-home test (and if the project is big enough it can allow you to skip the technical test altogether).
However the “downside” (but very soon to be an upside) is APIs require code and programmatic access to use them. It personally used to scare me as I thought APIs were too complex for me to use and only software engineers could make good use of them. If you are in the same situation I’m now going to show you that it’s far from the truth and that anyone can get started using APIs to gather data. I aim to give you enough tools that by the end of this post I hope you’ll be confident enough to get started on your own.
Digging into Elon Musk Tweets in Python Using the Requests Library
For this demo I’ll use the Twitter API. Together we will create a new Poetry project and set up everything we need to access the Twitter API. Our objective here is to retrieve Elon Musk tweets. By the end you’ll be able to use the same methodology to access any API of your choice. The authentication method can sometimes be different but the process should be roughly the same. Finally always make sure to read the documentation of the API you want to access, it will make your life way easier.
Prerequisites
- A Twitter developer account that you can request here
- A Github account and a repository for this project. I named mine twitter-api-blog-demo. Feel free to fork it and use it in our own account.
- SSH authentication to access your Github account. See here for details.
- An understanding of Poetry. I wrote about it in this blog post.
- Python 3+.
Initiate the Project Using Poetry
In your terminal run (replace the Github link and folder name with your own):
cd ~/Documents & git clone git@github.com:GuillaumeLegoy/twitter-api-blog-demo.git
cd twitter-api-blog-demo
Then initiate the poetry project, preinstall the requests library when prompted, by running:
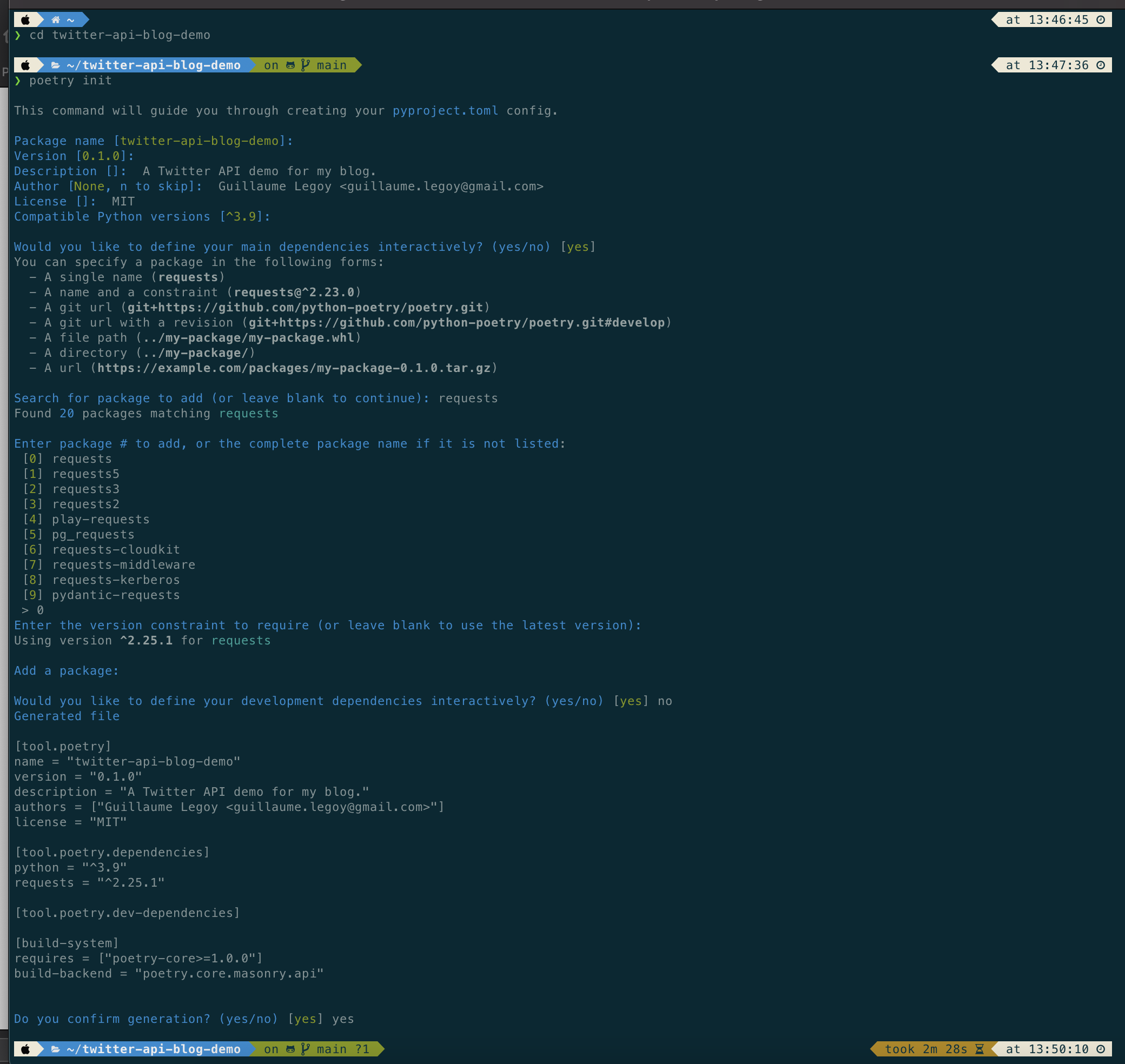
poetry init
The end result should look like this (replace what’s appropriate with your own info):
Finally start the virtual environment and install the Python libraries:
poetry shell
poetry install
Setup your Twitter API Authentication Key and Secret in Environment Variables
When you requested your Twitter developer account, they asked you to setup a project. Once done a page appears granting access to your key and token. Carefully save them somewhere safe and never share them with anyone. Also I’ll mention it now: never leave your API key and token in your code. This is bad practice and you’ll end up pushing it to Github and share your access with the world. Every time you do it a DevOps spirit appears and forces you to do 50 push-ups. It’s unpleasant and you don’t want that (and no it’s not a good excuse to get in shape). It’s always tempting to code something quick and dirty but when it comes to security, do it right.
Now for this exploratory demo we will use environment variables to store our key and token. However for a real application I would rather use something like AWS Secret Manager, which I introduced here.
Let’s set it up. In your terminal run:
export TWITTER_DEMO_KEY='YOUR-KEY'
export TWITTER_DEMO_SECRET='YOUR-SECRET'
export TWITTER_BEARER_TOKEN='YOUR-BEARER-TOKEN'
Query Elon Musk Tweets
Ok now for the fun part! Here we write a very basic Python script but that is litteraly everything you need to get started. It’s very important when building side projects to start simple and accumulates small wins along the way in order to avoid burn out and keep the project alive. We don’t build intricate applications or massive data pipelines in a few weeks. I’m personally not motivated to code every single day, and that’s perfectly fine. Start small, celebrate your achievements, and enjoy the ride.
Ok great, but can you show me the code now? Here it is:
import requests
import os
def get_bearer_token():
return os.environ.get("TWITTER_BEARER_TOKEN")
def get_author_tweets_url():
return "https://api.twitter.com/2/users/44196397/tweets"
def build_request_header():
return {"Authorization": f"Bearer {get_bearer_token()}"
if __name__ == "__main__":
elon_musk_tweets = requests.get(
get_author_tweets_url(), headers=build_request_header()
)
print(elon_musk_tweets)
Wait, that’s it? Yup! That’s all we need to get started. Create a file with the above code and run it in your terminal (change the name if needed):
python3 retrieve_elon_musk_tweets.py
The results will looke like this (remember the free API access is for the last 7 days of tweets so your results may vary):
{'data': [{'id': '1396698902842122244', 'text': '@Cointelegraph He fears the … https://t.co/78WzM5ICjA'}, {'id': '1396280083589976064', 'text': '@SpaceNews_Inc Congrats! @virgingalactic'}, {'id': '1396230120692543489', 'text': 'https://t.co/7afq6DIlzc'}, {'id': '1396226161718349824', 'text': '@flcnhvy @thatdogegirl @WhatsupFranks @TeslaGong Becoming multiplanetary is one of the greatest filters. Only now, 4.5 billion years after Earth formed, is it possible. \n\nHow long this window to reach Mars remains open is uncertain. Perhaps a long time, perhaps not. \n\nIn case it is the latter, we should act now.'}, {'id': '1396049958000685060', 'text': '@PPathole @SpaceX The hard part about Raptor is simplifying it'}, {'id': '1396049547680391168', 'text': '@TheRealShifo The true battle is between fiat & crypto. On balance, I support the latter.'}, {'id': '1396033766490087426', 'text': 'Any sufficiently advanced magic is indistinguishable from technology'}, {'id': '1395999086726189062', 'text': '@RocketRundown Welcome to the future. It’s gonna be great.'}, {'id': '1395902991601864705', 'text': '@jimfarley98 Congrats!'}, {'id': '1395823206901055488', 'text': '@cleantechnica Wow!'}], 'meta': {'oldest_id': '1395823206901055488', 'newest_id': '1396698902842122244', 'result_count': 10, 'next_token': '7140dibdnow9c7btw3w4sgl5saq0jsd3bu7o3lz7zfupk'}}
Before we continue let’s clarify a few points. The first get_bearer_token function retrieve the environment variable brearer token we added earlier. For more info on API keys and token, read here.
The second function get_author_tweets_url returns the URL that we query. Think of of it as the base of the query, the part that never changes. You’ll always find this URL in the documentation. API querying are basically the art of building URLs. However in this case we cheated a bit and added one variable in the link, the Twitter user id of Elon Musk (44196397). You may want to split this part from the query so it’s fed as an argument to the function.
Then the build_request_header builds the request header. The HTTP header sends important info with the request like in this case the authentication token, to make sure we have access. Headers are not to be counfounded with parameters which are the parts of the request that tells the server which data to extract (like a WHERE clause in SQL). For a better explanation on headers and parameters, read this piece. The requests library allows us to build custom headers and to pass parameters as well.
Lastly the request response is expressed as a JSON string. JSON is pretty much the standard way data is returned with most APIs. You need to become comfortable parsing it.
Finally the documentation for the above API request can be found here.
Going a Step Further by Retrieving Elon Musk Tweets Data in pandas
Let’s go one step further and add one function to the code as follow:
import requests
import os
def get_bearer_token():
return os.environ.get("TWITTER_BEARER_TOKEN")
def get_author_tweets_url():
return "https://api.twitter.com/2/users/44196397/tweets"
def build_request_header():
return {"Authorization": f"Bearer {get_bearer_token()}"
def extract_tweets_info(tweets_list):
for tweet in tweets_list.json()["data"]:
tweet_metadata_url = f"https://api.twitter.com/2/tweets/{tweet['id']}?tweet.fields=attachments,author_id,created_at,entities,geo,id,in_reply_to_user_id,lang,possibly_sensitive,referenced_tweets,source,text,withheld"
tweet_content = requests.get(
tweet_metadata_url, headers=build_request_header()
).json()
print(tweet_content["data"]["text"])
print(tweet_content["data"]["created_at"])
if __name__ == "__main__":
elon_musk_tweets = requests.get(
get_author_tweets_url(), headers=build_request_header()
)
extract_tweets_info(elon_musk_tweets)
The extract_tweets_info function takes the previously generated tweets_list and feeds the tweet['id'] of the previous response to a new URL "https://api.twitter.com/2/tweets/{tweet['id']}?tweet.fields= that is used to retrieve tweets content (documentation. Then we perform a request for each tweet and simply print the tweet text and the time it was created.
The function is a bit messy and does several things at the same time, which probaby warrants further breakdown in separate function. However I simply wanted to illustrate how quickly and easily we can have fun with an API.
Going a step further we could extract the data for each tweet into a dataset and performs some basic analysis on Elon Musk tweets. Your can quickly get creative! I believe you are now sufficiently prepared to get ready to tackle any API of your choice. Feel free to ask questions in the comments if anything wasn’t clear.
Happy coding!