The Importance of Structuring Data Projects: Github and Cookiecutter
Table of Content
Why do we Need to Structure our Data Projects?
As a data professional and part of a team you’ll spend more time reading other people code than writing your own. Code you read can be either from your colleagues or publicly available libraries. Most of the time you expect it to be well formatted, organized and documented if possible so that you don’t spend hours deciphering spaghetti code or navigating a complex file repository.
On the other hand this also means that as data scientists we should provide others, colleagues or external consumers of our code, with the same high quality project structure we expect them to provide for us. This is something we don’t necessary learn at the university or are overly concerned with when we start our career. You probably read multiple times on Twitter jokes about data science projects folders full of file1_v1.2_FINALX.ipynb files. While they are funny, I wish I realized earlier the power of structuring my analytics projects.
Luckily for us, simple tools exist to take our game to the next level and structure our projects, namely Version Control Systems (VCS) and Cookiecutter templates. These tools are most often used by software engineers, and I believe as data scientist we should try to emulate software engineering best practices. This is not the “sexiest” part of data science and sounds less interesting than exploring the latest AI/ML trend, but as a beginner I believe nothing else will add that much value as quickly as using these 2 tools and concepts. Here is a quick overview of the advantages of using them:
- Reproducibility: your files and analysis will lie in a remote repository for everybody with access right to access, making it easy to replicate your work.
- Collaboration: VCS like github allow you to create what is called branches to work on your own on a derived (“branched”) main branch often called master. This in turn make sure that 2 analysts don’t modify the same set of files creating weird bugs and mayhem down the line.
- Code quality: a well maintained repository will help with the quality of your code and you won’t be ashamed to share it with the world.
The rest of this post will show you how to set up your project in github and how to structure it using the Cookiecutter data science project template.
Setup a Github Repository
Please note these steps will mostly be the same with other version control system (Gitlab or Bitbucket for instance).
Create a New Repository
- Head over to https://github.com/ and create an account if you don’t have one.
- Create a new repository that will contain your project code.
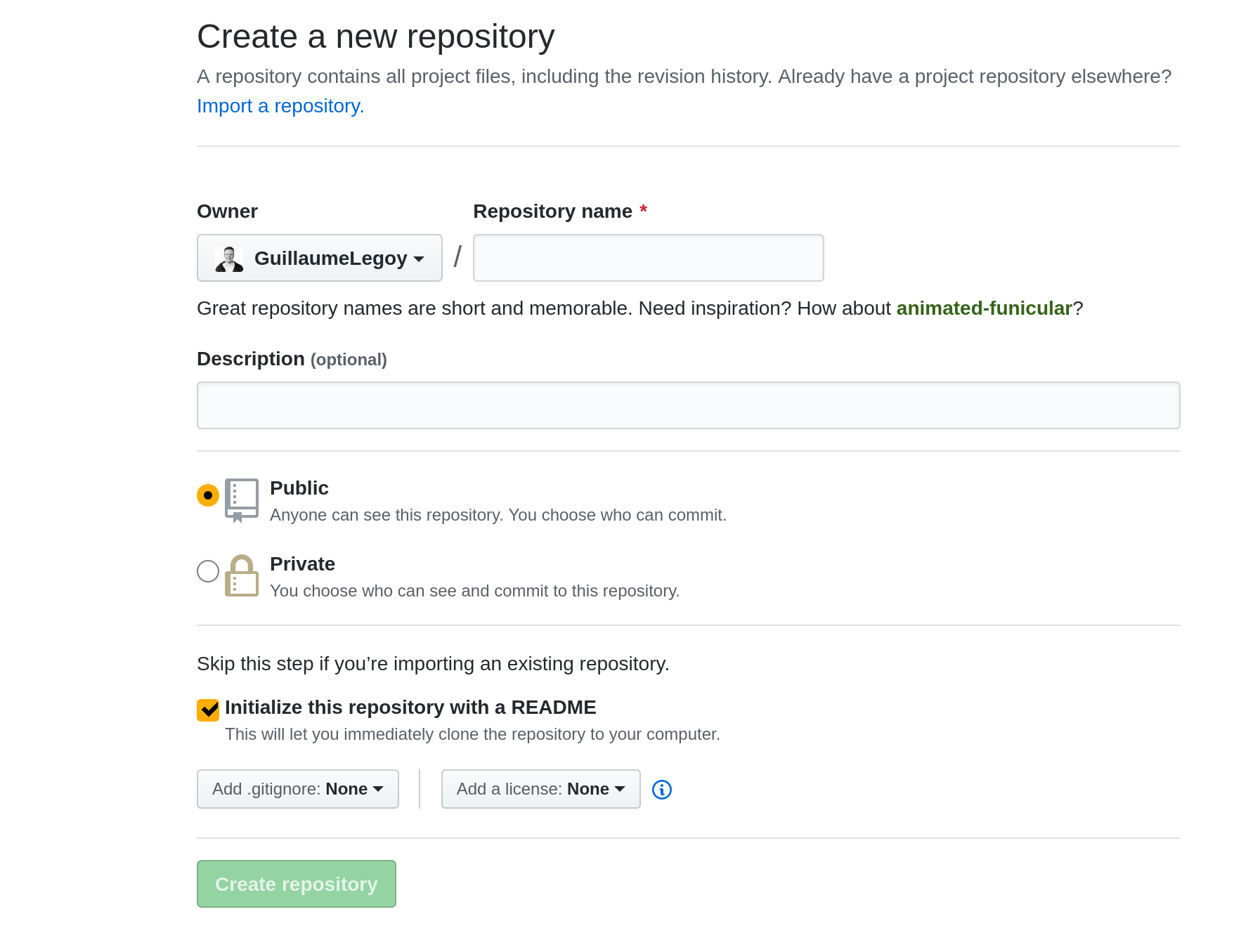
- Fill out your repo name (the simpler the better), if it’s public or private, and click “Initialize this repository with a README”, this is where you gonna add a description of your project for everyone to see.
That’s it congratulations you created your first repository! Now we want to be able to add our project code to it.
Clone your Project Locally
- Copy the link to your repository.
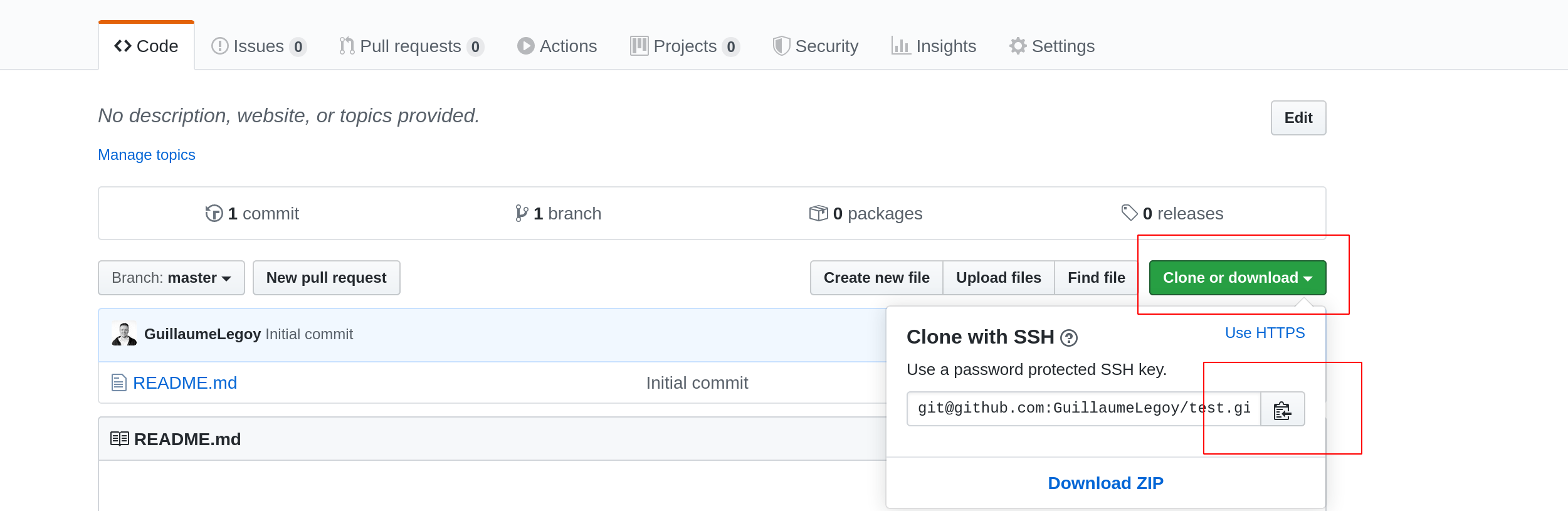
- Now on your local machine open a terminal and navigate to where you want to have your project repository, in my case the Document folder.
cd /home/guillaumelegoy/Documents/
- Clone your repository here using the link we copy pasted in the above step, this will create a copy of your repo files on your local machine. Enter your github credentials.
git clone https://github.com/GuillaumeLegoy/test.git
Great, you are done, you cloned your new project repository!
… but what if my project already exists and I want to clone it to the empty repository we created on github? In that case you’ll want to “link” your local project to your github repo. To do so enter the following commands in the terminal inside your project directory, they will initialize a new git project and push the files to the remote location in github.
pip install cookiecutter
git init
git add .
# The dot here means "add all the new / modified files."
git commit -m "Initial commit of local project."
# -m stands for message so that others know what you commited.
git remote add origin https://github.com/GuillaumeLegoy/test.git
git push origin master
Now you are all set! You can follow the same process minus git init to add future changes to your master branch. Here is an example of how to add the file awesome_script.py to your newly created repo:
git add awesome_script.py
git commit -m "Created an awesome script that does magic."
git push origin master
These 3 lines will get you a long way and are what I use 99% of the time.
You can however read up online git tutorials to learn more about git, as we only scratched the surface! For further usage and tricks, please consult one of the many great tutorials available online. For instance:
One final word of advice: never ever push credentials (passwords, tokens, ssh keys) to a remote repository. This is unsafe and your local devops engineer will be seriously mad at you.
Structure your Project with Cookiecutter Data Science
I strongly suggest you read the complete documentation here. It’s clear, concise, and explain everything you need to know. However if you just want to get started right now and play with it, creating a repository with a cookiecutter data science structure is as simple as typing this in a terminal:
pip install cookiecutter
cookiecutter https://github.com/drivendata/cookiecutter-data-science
That’s it, you can now customize your structure as you wish and push your changes to an existing remote repository following the steps described above. If you want to go one step further you can create your own theme.
I created my own template for my various projects. It’s a more minimalistic version that suits my needs better. Feel free to use it.
Happy coding!