Improving Data Quality Through Systematic Testing in SQL in dbt
Table of Content
SQL Code Needs to be Tested and Validated Like Any Other Programming Language.
I already wrote about why writing tests for our code is one of the best habits we can adopt. Some of the many benefits of testing include saving time, improving collaboration, and checking our code actually works. However while the practice of testing is usually well understood and put into practice by data scientists when writing Python code (or any other language), we can’t exactly say the same when it comes to SQL. Testing SQL code is often from experience an afterthought, for one or several of the following reasons:
- Lack of time. As analysts or data scientists we have to churn out reports and gather insights at the speed of light. Which means we often write SQL and forget about it and at best version control it for later copy pasting, both being incredibly time consuming and error-prone when it’s time to reuse it.
- Complexity. While it’s pretty simple to get started with testing in Python with great libraries like Pytest, SQL testing tools are lacking. A quick google search returns solutions that are not very user friendly.
- Reliability. Unit testing usually mocks functionalities of our code in isolation to test that specific parts of it are working. SQL depends on a database infrastructure, and while it’s doable it’s still quite cumbersome to mock a database, ingest fake data, and test our SQL returns the expected result. Moreover if we were to test during a maintenance window or when the DB is down for some reason, tests would fail even though our code is clean and does what it’s supposed to do.
So are we doomed to never be able to easily test our SQL? Fortunately we aren’t, thanks to dbt. dbt (data build tool) is a (fantastic) tool I presented in my previous blog post so please read it as I will use it in this article to demonstrate through concrete examples how we can use it to make testing our SQL code a breeze. But before we dive into the code, here is why I believe testing SQL is paramount and should be an integral part of our workflow as data scientists and analysts:
Trust in the data. I can’t stress this one enough. Let’s say we are building a report for our manager extracting revenue numbers for the last month using Table A in our database. Another colleague reporting to another executive does the same but using Table B (let’s assume we can get revenue data from 2 different tables for the sake of this example). However because the data quality in both tables wasn’t tested and because we both wrote different queries we end up reporting different numbers to different people. These two people then have a discussion and realize the issue and decide to never trust our numbers again. It is our job as data professionals to maintain this trust by checking our data quality!
Time gains and mature workflow. If our SQL is tested, valid, and version controlled, it becomes way easier to reproduce analysis and even automate them. Our SQL code should be treated as any other language and part of continuous development and integration cycle.
Now on to the fun part. In the rest of this blog post we will discover how to use dbt to test our SQL code. Again if you are not familiar with dbt please read this introduction as it explains how to set up a dbt project and the basic functionalities we will use now. The example database and project is also the same we used in that previous article: importing and analyzing cards from the Legend of Runeterra game made by Riot. As usual I’ll post screenshots so you can follow even if you don’t replicate my setup or have access to your own database.
Testing SQL in dbt
Put simply, dbt allows us to execute SQL through SELECT statements on existing raw data in order to create tables or views in our database. Testing happens once the data is present in our DB. This makes sense intuitively as if there is no data there is nothing to test against. Let’s also note that in this case we don’t test the raw data directly. We test our transformation of the raw data into analytics data. This is a pretty important distinction because we don’t want to test others code, only ours. If we want to test how the raw data is originally created and inserted into our database, this needs to happen upstream at the time of ingestion. Finally in order to get started I build my tables from scratch as follow (again, this part was covered in my introductory articles on dbt):
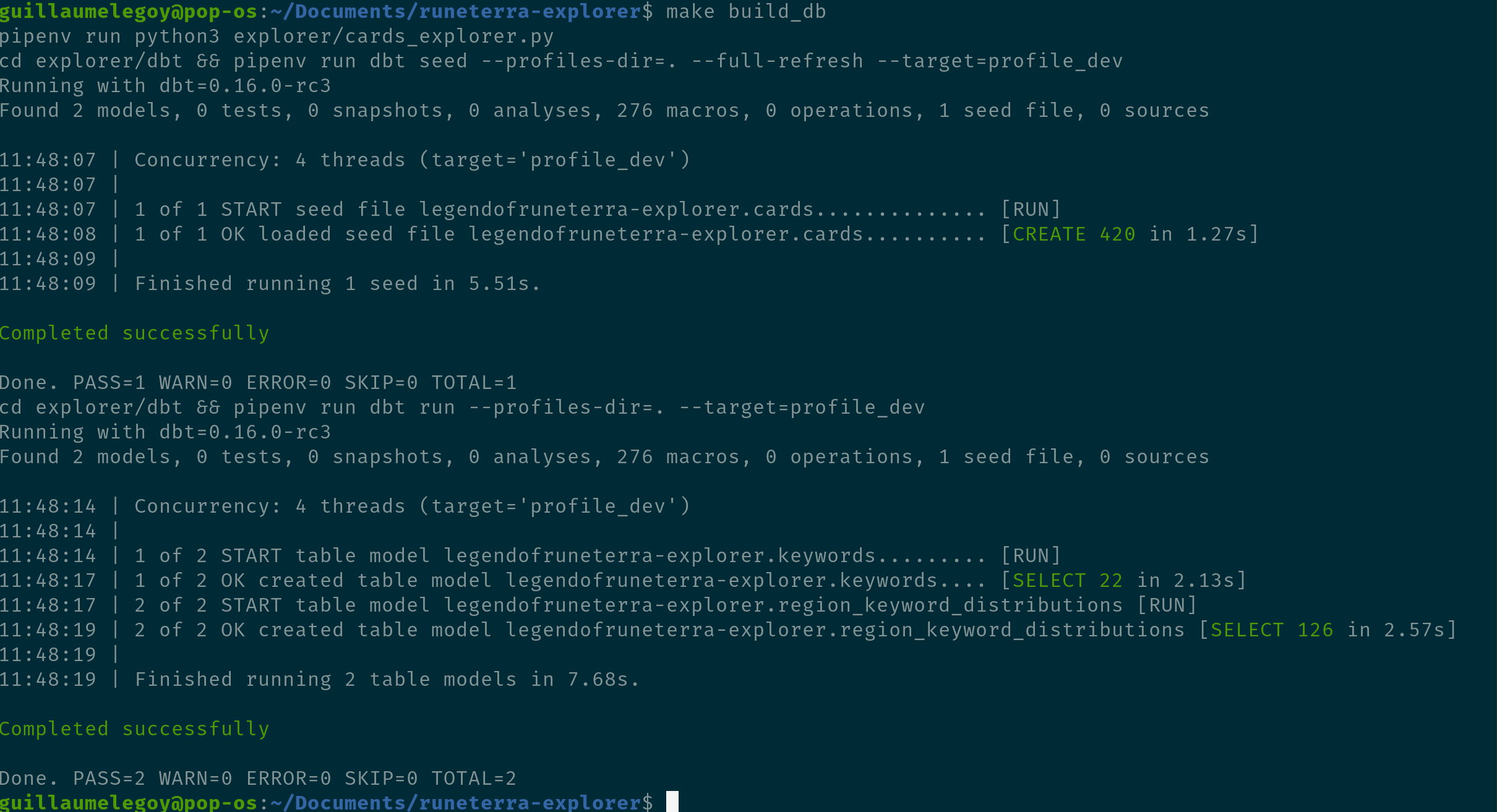
Alright everything is green which means tables were successfully created. However that doesn’t mean the data is right. Let’s test it!
schema.yml files
Before we get started we need to cover an important file of any dbt project. Indeed, dbt tests and tables description live in schema.yml files. A schema.yml file is an optional file which documents and run tests on our models (the SELECT statements used to create tables). It’s optional because our code will run and work without it, but in order to document and test these models we need to create that file, so it’s highly suggested to include it. One or multiple schema.yml files can exist in our models folder. For simple projects one is enough, but if we have multiple sub-folders it can be good to create one per sub-folder to avoid confusion, especially as these files can quickly contain a lot of lines. More info about these files can be found in the doc. This is where this file is located in my project:
dbt out-of-the-box tests
We will use the above schema.yml file to describe and tests data from the cards seeds model. As a reminder a seeds model is simply a static .csv file that we convert into a table in our database. The cards model is the entire collection of cards for the game, so we need it to be error-free if we want to perform any kind of meaningful analysis on it. dbt offers 5 types of test that can be used out-of-the-box in schema.yml files:
- not_null: checks that a column doesn’t contain NULL values
- unique: checks each value is unique
- accepted_value: checks that column values are contained within a provided list
- relationships: checks values from a table are contained in a parent table (referential integrity)
- expressions: this one is not technically out-of-the-box but part of the
dbt_utilspackage. It allows us to use SQL expression to test against specific values.
Let’s see some of these tests in action. This is what the schema.yml looks like for the cards model:
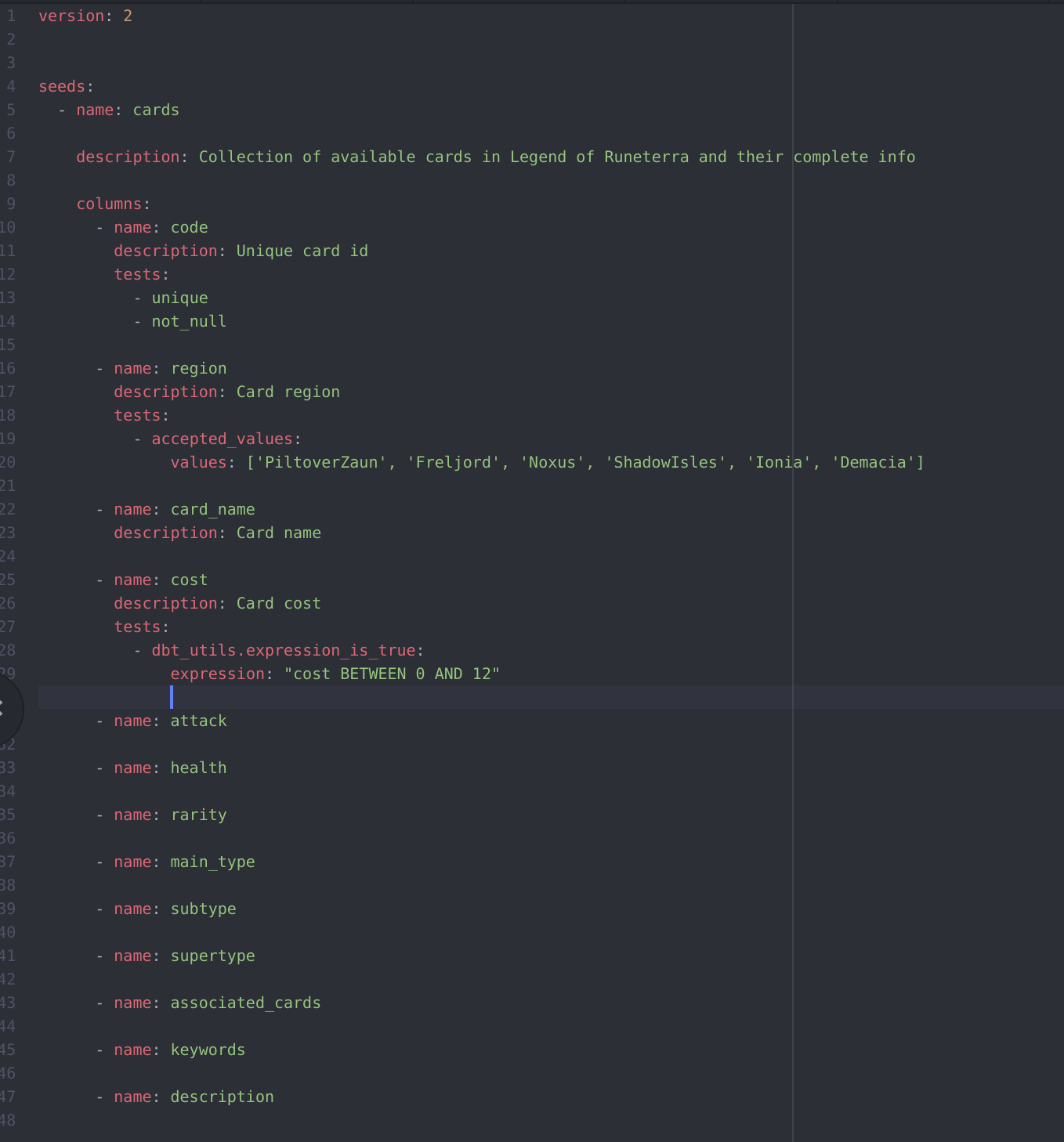
First we can see it’s a seeds model on the 4th line (it would be replaced by models if the table was created by a SQL statement found in the models folder). Then we have the name and description of this model on the 5th and 7th lines respectively, and finally the columns part on the 9th line that list every columns that is available in that table (code, region, cost, etc.). We can then see that some columns have a description and test fields. I didn’t do it for all of them for this example, but in a real life scenario we would want all of them to be complete with a description and appropriate tests.
Here 3 columns have tests:
- code
For this column we test that this column can’t be NULL and must be unique. Indeed this is the card id and we don’t want duplicated cards in our dataset. Also every card should have a code.
- region
In the game, cards come from 6 distinct regions. We use the accepted_values test to make sure each value in this column matches at least one in the following array: ['PiltoverZaun', 'Freljord', 'Noxus', 'ShadowIsles', 'Ionia', 'Demacia']. Note that we don’t need to use the not_null test here because if a row returns NULL it already means it’s not part of the list, therefore the test would fail.
- Cost
The cost of cards can range from 0 to 12. In order to make sure of this we use the dbt_utils.expression_is_true test with the expression cost BETWEEN 0 AND 12 (dbt_util refers to the package of the same name, see here for documentation about packages). For this test dbt will look for any value outside the 0-12 range and make the test fail if it finds any.
Running tests
The command to run test is almost identical to the one used to run our models that we’ve seen in the introductory article:
pipenv run dbt test --profiles-dir=. --target=profile_dev
Instead of running dbt run using pipenv, we use the dbt test command. This is the output:
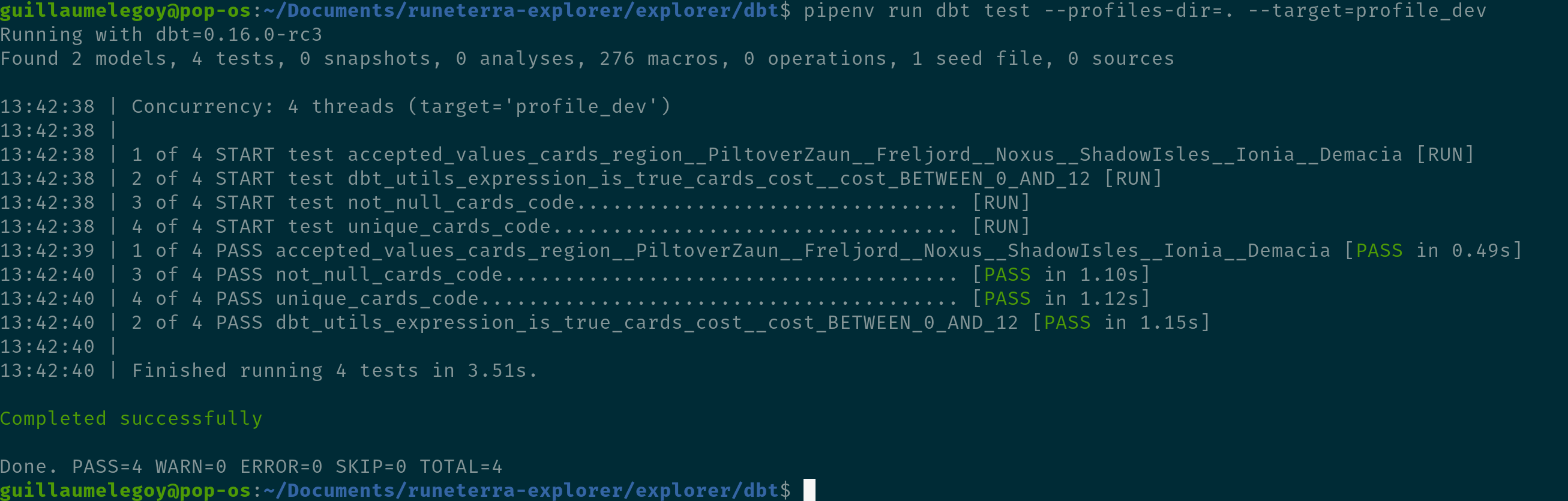
All the tests are green! This means the data answers our business logic for the 3 columns we described above. This is great because now we can have full confidence in the data when we create analysis and reports using it. In addition we can clearly see in the command line output the 4 tests dbt ran, one per line, with descriptions like START test accepted_values_cards_region__PiltoverZaun__Freljord__Noxus__ShadowIsles__Ionia__Demacia. This is helpful for when we need to debug why tests are failing (without this verbose output we wouldn’t know which test failed). In this case it would be easy to figure it out, but when thousands of tests are running at once it could become quite messy.
Let’s now see what happens when a test fails. To simulate wrong data I’ll change the content of the region array to ['PiltoverZaun', 'Freljord', 'Noxus', 'ShadowIsles', 'Ionia', 'Banana'] by replacing Demacia with Banana. Here is the new test output:
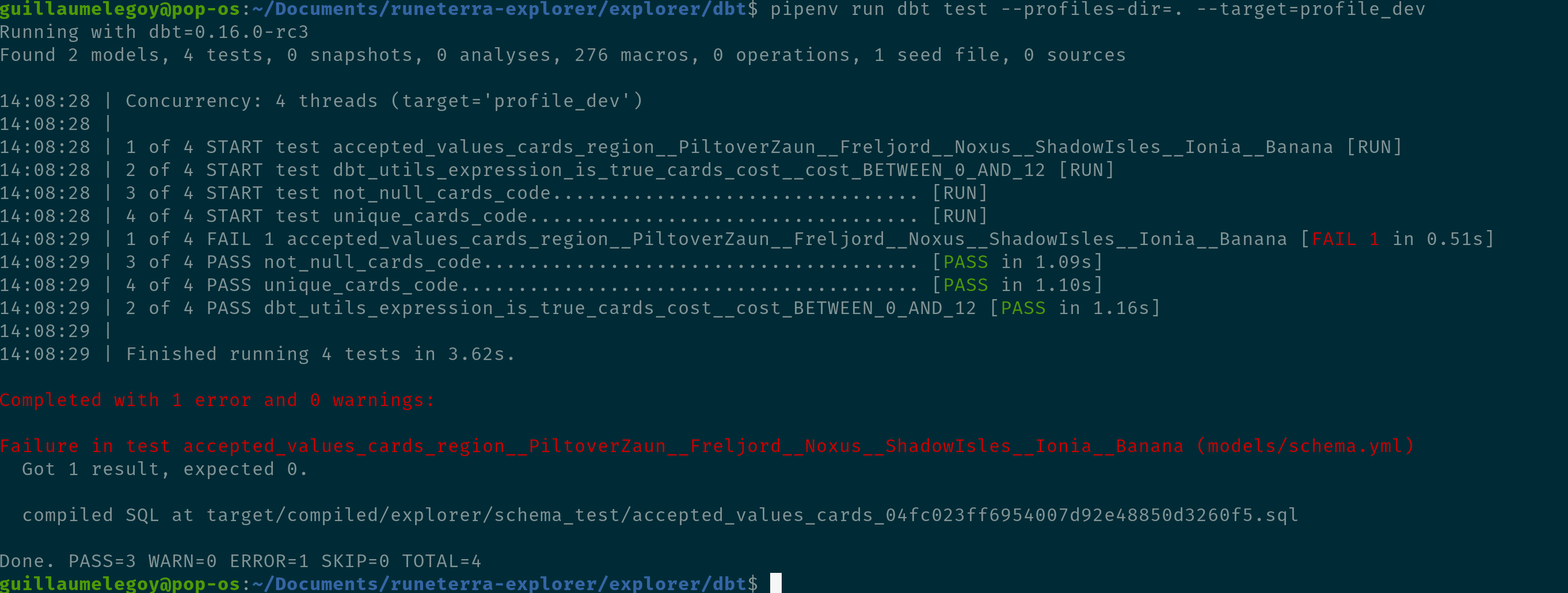
Tests are now failing! Fortunately dbt tells us which one, and how many values of that test failed, 1 in this case because it founds 1 different value that doesn’t match the provided list (this is not the count of wrong rows which I used to believe it was at first).
Going further with custom tests
Finally, it sometimes happens we want to test logic in our data tables that dbt out-of-the-box options don’t cover. Thankfully dbt implemented a cool functionality to test more complicated logic by allowing us to write custom SQL test code. These SQL scripts live in the tests folder by default, and in order for dbt to find them and understand they are tests, the path must be added to the dbt_projects.yml file like this: test-paths: ["tests"]. This how it looks like in our example project:
As an example I created the assert_ionia_health.sql test file:
SELECT
*
FROM
{{ ref('cards') }}
WHERE
health > 6 AND
region = 'Ionia'
It happens that in the game the Ionia region doesn’t have any card with more than 6 health. This is what we want to test here (ultimately we could use the dbt_utils.expression_is_true to check this condition, but this is so you get the idea behind custom test files). dbt executes custom test files and marks them as passed if it returns exactly 0 rows. So here we are asking dbt to “return all the rows from the cards table where the region column is equal to ‘Ionia’ and the cost column is greater than 6” by testing against it since it shouldn’t happen. The output:
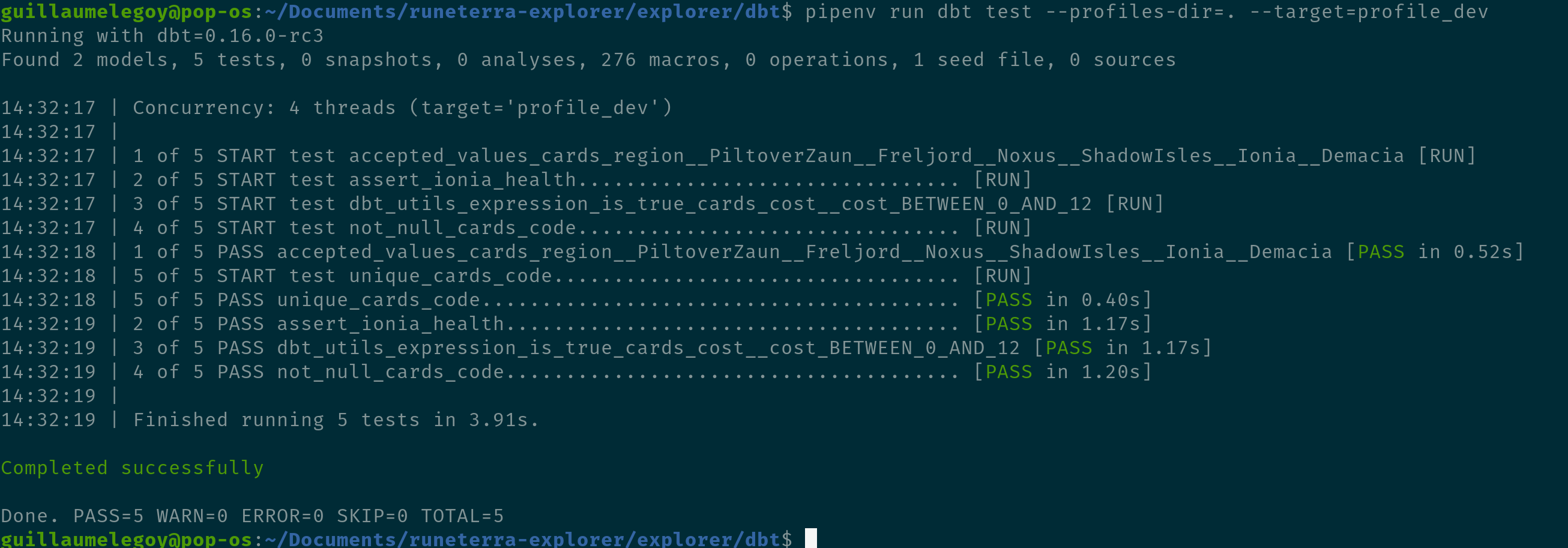
We can see our custom test file was correctly picked up by dbt and added to the list of tests, which are all green! This test was fairly trivial but complicated logic can be tested the exact same way.
That’s it, you can now get started writing tests for your analytics pipelines. I hope I convinced you of the benefits of testing SQL code and of the powerful simplicity of dbt to carry out data quality tests. Finally check out the official documentation to learn more about testing with dbt.
Happy coding!